Introduction
Si vous pratiquez un peu hadoop, vous n’êtes pas sans ignorer l’existence de l’API native Java « hadoop fs » prenant en charge les opérations sur système de fichiers telles que la création, le renommage ou la suppression de fichiers des répertoires, mais aussi la lecture ou l’écrire des fichiers.
Cela est idéal pour les applications s'exécutant dans le cluster Hadoop, mais il peut y avoir des cas où une application externe, web par exemple, peut avoir besoin de manipuler HDFS. Ainsi, Hortonworks est à l’origine du développement d’une API supplémentaire prenant en charge ces exigences basé sur des fonctionnalités
standards du protocole REST (REpresentational State Transfer).
Ce protocole REST est un « style » architectural ainsi qu’un mode de communication utilisé dans le développement de services Web. A noter que le recours à REST est souvent privilégié par rapport au SOAP, plus lourd.
En effet, REST est moins consommateur en bande passante, ce qui rend son utilisation plus pratique sur Internet.
Hadoop, plusieurs chemin pour atteindre ses données sur HDFS
Tous les chemins mènent à Rome, mais pour HDFS pas d'expression proverbiale latine mais plusieurs outils accessible pour vous mener aux données stockées sur HDFS.
- FileSystem (FS) shell commands
- WebHDFS
- HttpFS
Hadoop WebHDFS REST API
WebHDFS est basé sur les commandes HTTP classiques GET, PUT, POST et DELETE. Ainsi les opérations OPEN, GETFILESTATUS, LISTSTATUS s’appuient le HTTP GET, les opérations comme par exemple CREATE, MKDIRS, RENAME, SETPERMISSIONS sont relayées via du HTTP PUT. Enfin, les APPEND passent par du HTTP POST, tandis que le DELETE utilise, en toute logique, HTTP DELETE.
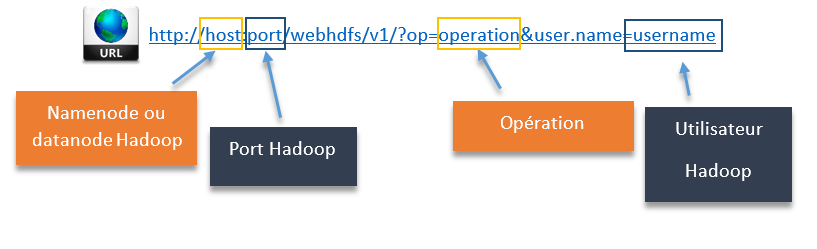
Pour la partie autorisation, l’utilisateur est passé à hadoop par l’intermédiaire d’un paramètre user.name, élément par entière de la requête http (dans « l’url » donc) ou lié directement à Kerberos le cas échéant
De façon simple, voici à quoi ressemble le format d’une URL utilisant WebHDFS REST API :
Si vous avez commencé à pratiquer, vous avez sans doute constaté que, dans certains cas l’exécution d’une commande, le namenode retourne une URL à l'aide du mécanisme de redirection temporaire HTTP 307 en précisant une URL de localisation faisant référence au datanode approprié.
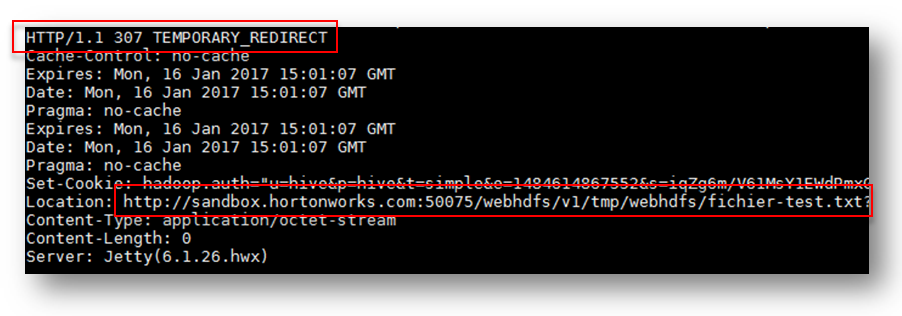
Ensuite, et dans ce cas, vous devez suivre cette URL pour exécuter les opérations de fichier sur ce datanode particulier. J’en reparlerai plus-tard, pas de panique.
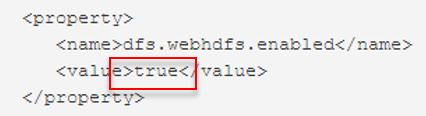
Une dernière chose, vérifiez bien votre configuration (
hdfs-site.xml) pour vous assurer que WebHDFS est actif (
dfs.webhdfs.enabled)
Quelques exemples
Maintenant que la théorie est comprise, du moins je l’espère, passons à la pratique.
Je vous propose donc quelques exemples pour vous familiariser avec le fonctionnement de l’Api.
Avant de vous lancer corps et âme dans l’aventure, je vous invite à jeter un coup d’œil à la commande système « curl » utilisée dans nos exemples.
- Vérifier le statut d’un répertoire WebHDFS
Dans ce premier exemple, nous allons vérieir l’existence du repertoire HDFS /tmp. Nous utilisons l’utilisateur hive pour nous connecter. Le namenode hadoop est accessible sur l’ip 172.28.203.244 et le port 5070. La commande est donc la suivante :
curl -i http://172.28.203.244:50070/webhdfs/v1/tmp?user.name=hive&op=GETFILESTATUS">http://172.28.203.244:50070/webhdfs/v1/tmp?user.name=hive&op=GETFILESTATUS
Cette commande retourne les informations au format JSON :
{"FileStatus":{"accessTime":0,"blockSize":0,"childrenNum":11,"fileId":16386,"group":"hdfs","length":0,"modificationTime":1484578587086,"owner":"hdfs","pathSuffix":"","permission":"777","replication":0,"storagePolicy":0,"type":"DIRECTORY"}}
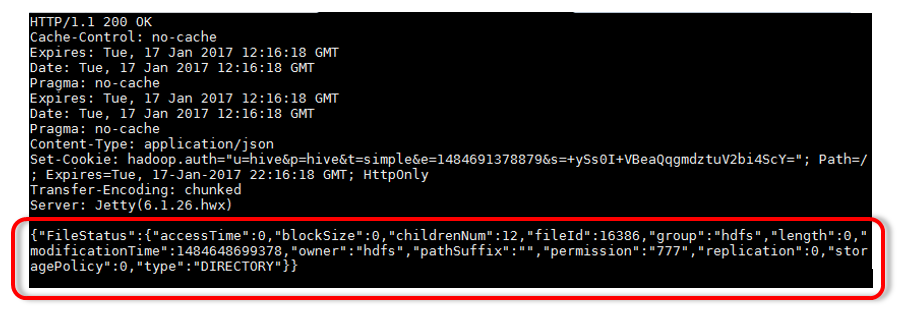
Le répertoire /tmp existe bien et nous pouvons visualiser ses paramètres (type, propriétaire, droits…)
Si le répertoire testé n’existe pas, le retour JSON sera de la forme :
{"RemoteException":{
"exception":"FileNotFoundException",
"javaClassName":"java.io.FileNotFoundException",
"message":"File does not exist: /missing_dir"
}}
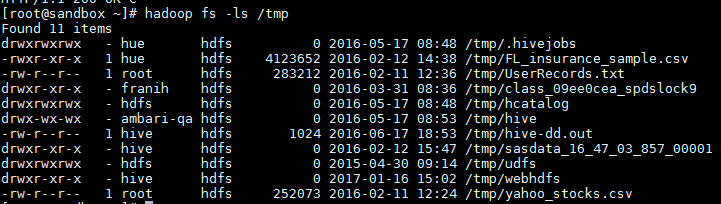
L’utilisation de la commande GETFILESTATUS est équivalente à l’exécution d’une commande hadoop fs, telle que :
hadoop fs -ls /tmp
Pour créer un répertoire nous utilisons l’opération MKDIRS et, notez bien, l’utilisation d’un HTTP PUT :
curl -i -X PUT http://172.28.203.244:50070/webhdfs/v1/tmp/testwebhdfs?user.name=hive&op=MKDIRS">http://172.28.203.244:50070/webhdfs/v1/tmp/testwebhdfs?user.name=hive&op=MKDIRS
Le JSON de retour peut-être :
{"boolean":true}
Ou par exemple :
{"RemoteException":{
"exception":"AccessControlException",
"javaClassName":"org.apache.hadoop.security.AccessControlException",
"message":"Permission denied: user=hive, access=WRITE, inode=\"/\":hdfs:hdfs:drwxr-xr-x"}}
L’exception java (Permission denied ) permet un premier niveau d’analyse.
Attention, les choses se compliquent un peu (à peine). En effet, la création d’un fichier nécessite deux étapes. La première consiste à interroger le namenode afin que celui nous « indique le chemin » vers le datanode qui va bien. C’est dans une seconde étape, sur ce datanode, que nous créons le fichier. Compris ?
Etape 1
On indique au namenode, via l’opération CREATE que nous souhaitons créer un fichier.
curl -i -X PUT "http://172.28.203.244:50070/webhdfs/v1/tmp/webhdfs/fichier-test.txt?user.name=hive&op=CREATE"
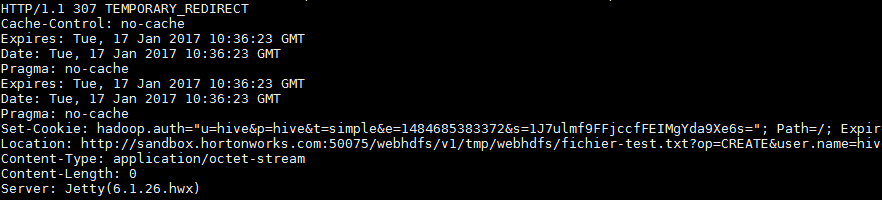
la commande ne retourne aucun JSON mais une redirection temporaire HTTP 307. Cela vous dit quelque chose bien sur puisque j’en ai parlé au début de cet article.
Aussi, la commande CREATE exécuté sur le namenode retourne, via « Location », l’url à suivre, sur le datanode , pour créer le fichier :
Maintenant que la première étape nous a « indiqué » l’URL à suivre nous pouvons injecter notre fichier :
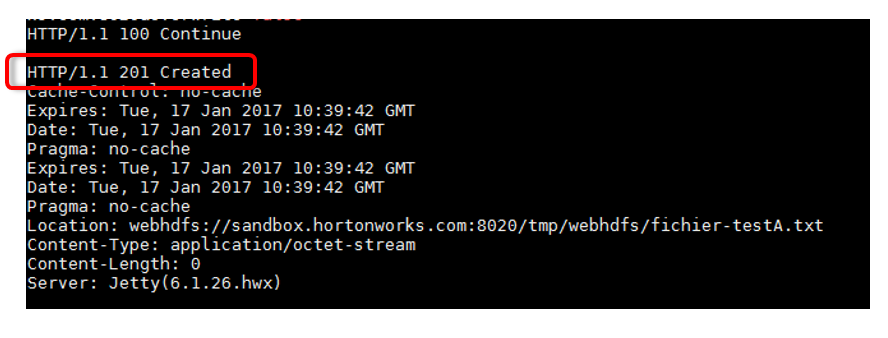
curl -i -T fichier-test.txt http://172.28.203.244:50075/webhdfs/v1/tmp/webhdfs/fichier-testA.txt?op=CREATE&user.name=hive&namenoderpcaddress=sandbox.hortonworks.com:8020&overwrite=false">http://172.28.203.244:50075/webhdfs/v1/tmp/webhdfs/fichier-testA.txt?op=CREATE&user.name=hive&namenoderpcaddress=sandbox.hortonworks.com:8020&overwrite=false
Vous devez obtenir un
HTTP 201 Created
Conclusion
Comme nous l’avons vu, WebHDFS fournit un moyen simple et standard d'exécuter les opérations du système de fichiers Hadoop par un client externe qui ne s'exécute pas nécessairement sur le cluster Hadoop lui-même. Une exigence toutefois : Le client doit avoir une connexion directe à namenode et datanodes via les ports prédéfinis.
Enfin, pour aller plus loin, je vous invite à vous rendre sur le site officiel du projet :
https://hadoop.apache.org/docs/r1.0.4/webhdfs.html. Enfin n'oubliez pas M
a bibliothèque SAS Hadoop où je référence les documentations autour de SAS et des technologies Hadoop.












