
Ce mardi 4 juin au matin, je me trouvais dans l'effervescence du Keynote & Strategy Theatre au Tech Show de Francfort, pour une session qui a particulièrement retenu mon attention. Steffen Bischoff (
Technical Evangelist ) de Qlik y présentait "Iceberg ahead : Building an Open Source Lakehouse with Qlick Talend Cloud and Apache Iceberg." Ayant déjà eu l'occasion d'expérimenter avec Apache Iceberg, j'étais particulièrement impatient de découvrir un cas d'usage complet, et cette présentation promettait beaucoup.
La session a bien posé le contexte des défis actuels : jongler entre la structure parfois rigide des Data Warehouses et la flexibilité des Data Lakes qui peuvent, sans une gouvernance stricte, se transformer en "data swamps" (un entrepôt de données dans lequel croupissent des datas inutiles) . L'objectif est clair : briser les silos et maîtriser les coûts tout en valorisant au maximum nos actifs de données.

L'Open Lakehouse a été introduit comme la solution d'avenir, cherchant à unifier le meilleur des deux mondes. La pierre angulaire de cette ouverture est Apache Iceberg, ce format de table ouvert qui, pour l'avoir déjà un peu pratiqué, apporte des avantages indéniables : évolution de schéma facilitée, partitionnement intelligent, la fameuse capacité de "time travel" (Permet de reproduire des requêtes qui utilisent exactement le même instantané de table,) , et une gestion robuste des accès concurrents.
Steffen Bischoff a ensuite expliqué comment Qlick, via Qlick Talend Cloud et Talend Studio, s'inscrit dans cette démarche pour concrétiser la vision de l'Open Lakehouse. Et c'est là que, pour moi, la session a pris toute sa dimension : la véritable force résidait indéniablement dans les démonstrations présentées. Celles-ci étaient claires, concrètes et ont permis de visualiser la mise en œuvre des pipelines de données avec Iceberg, notamment l'intégration avec Snowflake. Cela a vraiment illustré le potentiel. Concernant la présentation elle-même, elle se voulait hyper fluide. Si ce rythme très dynamique a permis de couvrir un large spectre.
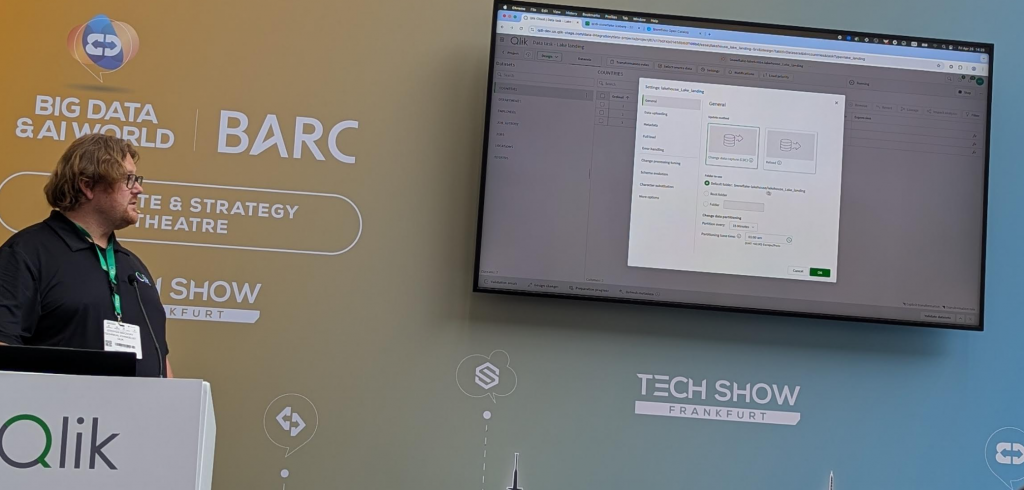
La véritable force de cette présentation résidait indéniablement dans les démonstrations présentées.
En conclusion, cette présentation a confirmé avec brio la pertinence de l'Open Lakehouse. Les démonstrations ont été un vrai plus, apportant une dimension pratique très appréciable. Pour quelqu'un comme moi, déjà sensibilisé à Iceberg, voir cette intégration poussée avec les outils Qlick était une excellente source d'inspiration. On repart avec une vision claire des possibilités pour plus d'agilité et une meilleure gouvernance des données. Une matinée très enrichissante au cœur de l'innovation à Francfort !
![[DEBUG] Lister les tables, tables et colonnes d'un libname ODBC](/wp-content/uploads/2017/02/debug-odbc.jpg)












